Active/Passive PostgreSQL Cluster, using Pacemaker, Corosync
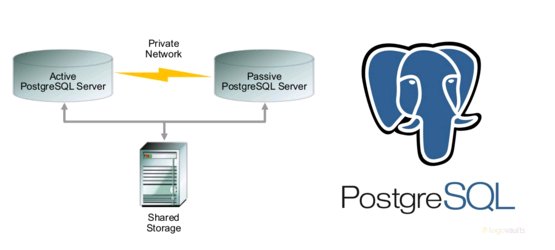
Description
This article describes an example of configuring Active/Passive PostgreSQL cluster, using Pacemaker, Corosync. As the disk subsystem is considered the drive from the system data storage (CSV). Similar to the Windows Failover Cluster from Microsoft.
Technical details:
OS Version — CentOS 7.1
Version package pacemaker — 1.1.13-10
Package version pcs — 0.9.143
PostgreSQL — 9.4.6
As servers(2pcs) — iron server 2*12 CPU/ memory 94GB
As a CSV(Cluster Shared Volume) — an array of class Mid-Range Hitachi RAID 1+0
Preparation of cluster nodes
Rule /etc/hosts on both hosts and make the visibility of hosts to each other by short names, for example:
the
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.66.23 node1.local.lan node1
10.1.66.24 node2.local.lan node2
Also make exchange between servers using SSH keys and split keys between hosts.
After this we need to make sure that both servers can see each other by short names:
the
[root@node1 ~]# ping node2
PING node2.local.lan (10.1.66.24) 56(84) bytes of data.
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=1 ttl=64 time=0.204 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=2 ttl=64 time=0.221 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=3 ttl=64 time=0.202 ms
64 bytes from node2.local.lan (10.1.66.24): icmp_seq=4 ttl=64 time=0.207 ms
[root@node2 ~]# ping node1
PING node1.local.lan (10.1.66.23) 56(84) bytes of data.
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=1 ttl=64 time=0.202 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=2 ttl=64 time=0.218 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=3 ttl=64 time=0.186 ms
64 bytes from node1.local.lan (10.1.66.23): icmp_seq=4 ttl=64 time=0.193 ms
The package installation to create the cluster
On both hosts set the required packages to then assemble the cluster:
the
yum install -y pacemaker pcs psmisc policycoreutils-python
Then start and turn on the service pcs:
the
systemctl start pcsd.service
systemctl enable pcsd.service
For cluster management we need a special user, create it on both hosts:
the
passwd hacluster
Changing password for user hacluster.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Pacemaker|Corosync
To check the authentication with the first node, run the following command:
the
[root@node1 ~]# pcs cluster auth node1 node2
Username: hacluster
Password:
node1: Authorized
node2: Authorized
Next, we start our cluster and check the state of the startup:
the
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
pcs cluster start --all
pcs status --all
A conclusion about the state of the cluster should be like this:
the
[root@node1 ~]# pcs status
Cluster name: cluster_web
WARNING: no stonith devices and stonith-enabled is not false
Last updated: Tue Mar 16 10:11:29 2016
Last change: Tue Mar 16 10:12:47 2016
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 Nodes configured
0 Resources configured
Online: [ node1 node2 ]
Full list of resources:
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Now go to configuring resources in a cluster.
setup CSV
Go to the first host and a custom LVM:
the
pvcreate command on /dev/sdb
shared_vg vgcreate /dev/sdb
lvcreate -l 100% FREE-n ha_lv shared_vg
mkfs.ext4 /dev/shared_vg/ha_lv
The drive is ready. Now we need to make sure what was on the disk was not applied a rule of automatic mount purpose for LVM. This is done by making changes in the file /etc/lvm/lvm.conf (partition activation) on both hosts:
the
activation {.....
#volume_list = [ "vg1", "vg2/lvol1", "@tag1", "@*" ]
volume_list = [ "centos", "@node1" ]
Updated initrams and reboot the nodes:
the
dracut -H-f /boot/initramfs-$(uname-r).img $(uname-r)
shutdown-h now
Adding resources to the cluster
Now you need to create a resource group in the cluster — drive c, file system and IP.
the
pcs resource create virtual_ip IPaddr2 ip=10.1.66.25 cidr_netmask=24 --group PGCLUSTER
pcs resource create DATA ocf:heartbeat:LVM volgrpname=shared_vg exclusive=true --group PGCLUSTER
pcs resource create DATA_FS Filesystem device="/dev/shared_vg/ha_lv" directory="/data" fstype="ext4" force_unmount="true" fast_stop="1" --group PGCLUSTER
pcs resource create pgsql pgsql pgctl="/usr/pgsql-9.4/bin/pg_ctl" psql="/usr/pgsql-9.4/bin/psql" pgdata="/data" pgport="5432" pgdba="postgres" node_list="node1 node2" op start timeout="60s" interval="0s" on-fail="restart" op monitor timeout="60s" interval="4s" on-fail="restart" op promote timeout="60s" interval="0s" on-fail="restart" op demote timeout="60s" interval="0s" on-fail="stop" op stop timeout="60s" interval="0s" on-fail="block" op notify timeout="60s" interval="0s" --group PGCLUSTER
Please note that all resources in a group.
Also don't forget to correct dafault -cluster parameters:
the failure-timeout=60s
migration-threshold=1
In the end, You should see something like:
the [root@node1 ~]# pcs status
Cluster name: cluster_web
Last updated: Mon Apr 4 14:23:34 2016 Last change: Thu Mar 31 12:51:03 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 nodes and 4 resources configured
Online: [ node1 node2 ]
Full list of resources:
Resource Group: PGCLUSTER
DATA (ocf::heartbeat:LVM): Started node2
DATA_FS (ocf::heartbeat:Filesystem): Started node2
virtual_ip (ocf::heartbeat:IPaddr2): Started node2
pgsql (ocf::heartbeat:pgsql): Started node2
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Check the status of PostgreSQL service on the host where the resource group:
the [root@node2~]# ps-ef | grep postgres
postgres 4183 1 0 Mar31 ? 00:00:51 /usr/pgsql-9.4/bin/postgres -D /data -c config_file=/data/postgresql.conf
postgres 4183 4204 0 Mar31 ? 00:00:00 postgres: logger process
postgres 4206 4183 0 Mar31 ? 00:00:00 postgres: checkpointer process
postgres 4207 4183 0 Mar31 ? 00:00:02 postgres: writer process
postgres 4208 4183 0 Mar31 ? 00:00:02 postgres: wal writer process
postgres 4209 4183 0 Mar31 ? 00:00:09 postgres: autovacuum launcher process
postgres 4210 4183 0 Mar31 ? 00:00:36 postgres: stats collector process
root 16926 30749 0 16:41 pts/0 00:00:00 grep --color=auto postgres
Check performance
The simulated drop in service on ноде2 and see what happens:
the [root@node2 ~]# pcs resource debug-stop pgsql
Operation stop for pgsql (ocf:heartbeat:pgsql) returned 0
> stderr: ERROR: waiting for server to shut down....Terminated
> stderr: INFO: PostgreSQL is down
Check the status on ноде1:
the [root@node1 ~]# pcs status
Cluster name: cluster_web
Last updated: Mon Apr 4 16:51:59 2016 Last change: Thu Mar 31 12:51:03 2016 by root via cibadmin on node2
Stack: corosync
Current DC: node2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
2 nodes and 4 resources configured
Online: [ node1 node2 ]
Full list of resources:
Resource Group: PGCLUSTER
DATA (ocf::heartbeat:LVM): Started node1
DATA_FS (ocf::heartbeat:Filesystem): Started node1
virtual_ip (ocf::heartbeat:IPaddr2): Started node1
pgsql (ocf::heartbeat:pgsql): Started node1
Failed Actions:
* pgsql_monitor_4000 on node2 'not running' (7): call=48, status=complete, exitreason='none',
last-rc-change='Mon Apr 4 16:51:11 2016', queued=0ms, exec=0ms
PCSD Status:
node1: Online
node2: Online
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
As we can see already feels great to ноде1.
ToDO: make dependent on resources within the group...
Literature:
clusterlabs.org

Comments
Post a Comment