The real-time processing of data in the AWS Cloud. Part 2
first part article we have described one of the challenges we faced when working on a public service for storage and analysis of results of biological research. Reviewed the requirements provided by the customer, and several options of implementation based on existing products.
Today we will talk about the decision, which was made.
the

Front-end
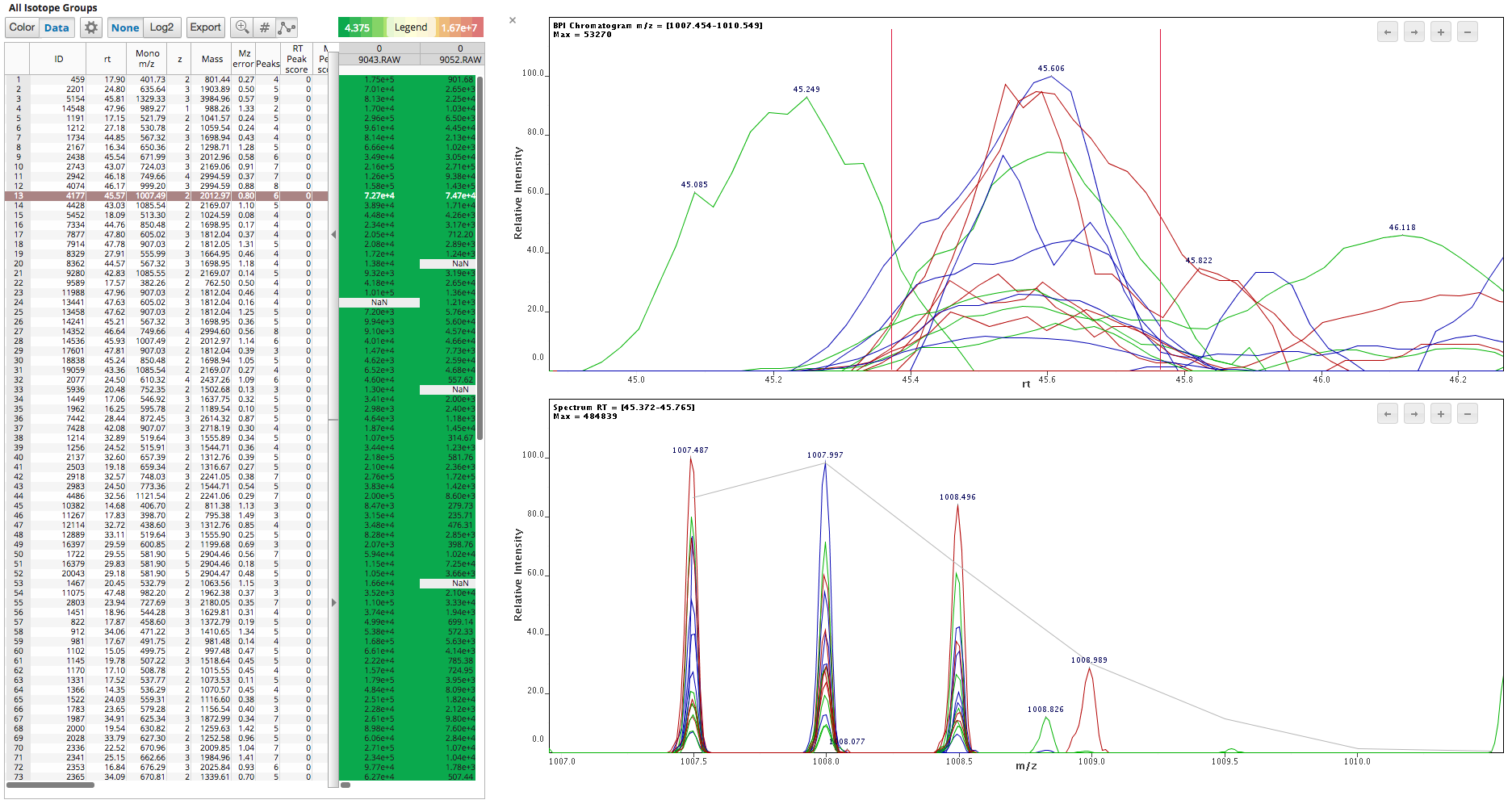
User requests arrive at front-end, validinputs for compliance with the format and transmitted to the back-end. Each query will eventually return to the front-end image or set of points, independently if the client wants to build such an image.
In the future it's possible to install LRU-cache to store duplicate results with a short shelf life items — commensurate with the duration of the user session.
Back-end
For each such query back-end
the
Processing of subtasks occurs through parallel Queuing each task in RPC-style (set the task, waited, received the result). To do this, use the thread pool, the global for back-end application. Each thread in this pool is responsible for the interaction with the broker: message sending, waiting, receiving the result.
Besides, using a thread pool of known size allows you to control the number of concurrently processed messages subtasks. And starting threads for processing the known subtasks gives the possibility to plan what common tasks are performed at the moment, predicting the timing of readiness of each of the common task.

For stability it is required to follow three things:
Paragraphs 2 and 3 are achieved by manipulation of the thread pool size and the approach to the formulation of the subproblems in turn. If you change the average processing time of podzamci (item 1) is required to increase or decrease the number of worker nodes processing the subtask.
Working units-sorcery
Subscribers to the RabbitMQ queue are standalone applications, which for definiteness we will call workere. Each of them occupies the whole of EC2 instances, most efficiently using CPU, memory and network bandwidth.
Subtasks are formed on the back-end, consumed some of workerb. The processing of this subtask does not imply a global context, because the worker works irrespective of their kind.
The important point is that Amazon S3 provides random access to any data. This means that instead of loading a file of size 500 MB, bomost of which are not needed for processing a given query, we can read only what you really need. That is, dividing the overall task into postacute the right way, you can always get a single out of the same data.
In the case of a runtime error (out of memory, failed, etc.), the problem just comes back in a queue that is distributed to another node automatically. For the stability of the system, each of workerb restarted periodically via cron, to avoid possible problems with memory leaks and overflow the JVM heap.
Scaling
Of the reasons leading to the need to change the number of nodes the applications can be multiple:
To solve problems 1 and 2 we used the APIs provided by EC2, and created a separate module-scaler that operates on instances. Each new instance is created on the basis of pre-configured operating system image (Amazon Machine Image, AMI) and runs through the spot requests, which allows you to save money on web hosting about five times.
The disadvantage of this approach is that from the inception of the spot instance request to its commissioning is about 4-5 minutes. By this time the peak load can already be passed, and the need to increase the number of nodes may disappear by itself.
To get into such a situation rarely, we use statistics on the number of requests, geographic location of users and time of day. With its help we increase or reduce the number of worker nodes “in advance”. Almost all users are working with our service exclusively during the working day. Therefore, the clearly visible spikes in the beginning of the working day in the States (especially US West) and China. And if you have problems with overloading the queues do arise, we have time to smooth them for 4-5 minutes.
Issue # 3 has yet to be resolved is for us the most vulnerable place. Current connectivity of three things: control access to data, knowledge about their specificity and location, and post-processing the computed data (the Reduce step), — is far-fetched and should be recycled in separate layers.
In fairness it must be said that the process is reduced to Reduce the System.arraycopy(...), and the total amount of data in memory (the query + part of the finished sub-tasks) on a single instance back-end has never exceeded the 1 GB that easily fit in the JVM heap.
Deployment
Any changes in the existing system through several stages of testing:
the
For the described subsystems changes in the basis weight, affect performance and to support new types of source data. Therefore, unit and integration testing, is usually sufficient.
After each successful build from the branch “production” publish TeamCity artifacts, which is a ready to use JAR-s and scripts that control a set of parameters to run the application. When starting a new instance from the AMI predpochtenija (or restart an existing one) starting script TeamCity uses the latest production build and launch the app using the supplied build script.
Thus, all you need to do for deployment of the new version in production to wait for the end of the tests and click on the “magic” button, restarting the instances. Controlling the set of running instances and sharing the task flow to different RabbitMQ queue, you can conduct A/B testing for user groups.
the
the
the
In this review article we have described our approach to solve a fairly typical problem. The project continues to evolve, becoming every day more and more functional. We are happy to share their experiences and answer your questions.
Article based on information from habrahabr.ru
Today we will talk about the decision, which was made.
the
the architecture
Front-end
User requests arrive at front-end, validinputs for compliance with the format and transmitted to the back-end. Each query will eventually return to the front-end image or set of points, independently if the client wants to build such an image.
In the future it's possible to install LRU-cache to store duplicate results with a short shelf life items — commensurate with the duration of the user session.
Back-end
For each such query back-end
the
-
the
- validates the incoming request and checks its legitimacy from the point of view of policy, security, the
- defines what data need to be read from S3, and generates a common goal, the result of processing which needs to return to the front-end the
- breaks tasks into subtasks, taking into account the features of the data location on S3 to avoid double out, etc. the
- puts tasks into the queue based on RabbitMQ the
- processes the results obtained from the queue by collecting sets of points together,
renders an image if the request involves it,
returns the results to the front-end.
Processing of subtasks occurs through parallel Queuing each task in RPC-style (set the task, waited, received the result). To do this, use the thread pool, the global for back-end application. Each thread in this pool is responsible for the interaction with the broker: message sending, waiting, receiving the result.
Besides, using a thread pool of known size allows you to control the number of concurrently processed messages subtasks. And starting threads for processing the known subtasks gives the possibility to plan what common tasks are performed at the moment, predicting the timing of readiness of each of the common task.
For stability it is required to follow three things:
-
the
- treatment of sub-tasks / sub-tasks that are queued to a point in time — if you increase this parameter requires to increase the throughput spabest the queue. the
- Prioritizing the processing of the subtasks, so that each common task was processed in the least possible time. the
- Number of common tasks in the processing to avoid overflow the JVM heap on the back end because of the need to store intermediate results.
Paragraphs 2 and 3 are achieved by manipulation of the thread pool size and the approach to the formulation of the subproblems in turn. If you change the average processing time of podzamci (item 1) is required to increase or decrease the number of worker nodes processing the subtask.
Working units-sorcery
Subscribers to the RabbitMQ queue are standalone applications, which for definiteness we will call workere. Each of them occupies the whole of EC2 instances, most efficiently using CPU, memory and network bandwidth.
Subtasks are formed on the back-end, consumed some of workerb. The processing of this subtask does not imply a global context, because the worker works irrespective of their kind.
The important point is that Amazon S3 provides random access to any data. This means that instead of loading a file of size 500 MB, bomost of which are not needed for processing a given query, we can read only what you really need. That is, dividing the overall task into postacute the right way, you can always get a single out of the same data.
In the case of a runtime error (out of memory, failed, etc.), the problem just comes back in a queue that is distributed to another node automatically. For the stability of the system, each of workerb restarted periodically via cron, to avoid possible problems with memory leaks and overflow the JVM heap.
Scaling
Of the reasons leading to the need to change the number of nodes the applications can be multiple:
-
the
- an increase in the average processing time of the subtasks that eventually leads to problems in the delivery of the final result to users in the required time frame. the
- Lack of proper load on the nodes worker. the
- Overload back-end on the CPU or memory consumption.
To solve problems 1 and 2 we used the APIs provided by EC2, and created a separate module-scaler that operates on instances. Each new instance is created on the basis of pre-configured operating system image (Amazon Machine Image, AMI) and runs through the spot requests, which allows you to save money on web hosting about five times.
The disadvantage of this approach is that from the inception of the spot instance request to its commissioning is about 4-5 minutes. By this time the peak load can already be passed, and the need to increase the number of nodes may disappear by itself.
To get into such a situation rarely, we use statistics on the number of requests, geographic location of users and time of day. With its help we increase or reduce the number of worker nodes “in advance”. Almost all users are working with our service exclusively during the working day. Therefore, the clearly visible spikes in the beginning of the working day in the States (especially US West) and China. And if you have problems with overloading the queues do arise, we have time to smooth them for 4-5 minutes.
Issue # 3 has yet to be resolved is for us the most vulnerable place. Current connectivity of three things: control access to data, knowledge about their specificity and location, and post-processing the computed data (the Reduce step), — is far-fetched and should be recycled in separate layers.
In fairness it must be said that the process is reduced to Reduce the System.arraycopy(...), and the total amount of data in memory (the query + part of the finished sub-tasks) on a single instance back-end has never exceeded the 1 GB that easily fit in the JVM heap.
Deployment
Any changes in the existing system through several stages of testing:
the
-
the
- Unit-testing. This process is integrated into the build is running on TeamCity after each commit. the
- Integration testing. Once a day (sometimes less) TeamCity runs multiple builds that verify the interaction between modules. As test data we use pre-prepared files, the result of the processing are known. With the expansion of the set of functional features, we add specific cases in your test code. the
- If the changes affect the UI, it sometimes requires human intervention at the final stage.
For the described subsystems changes in the basis weight, affect performance and to support new types of source data. Therefore, unit and integration testing, is usually sufficient.
After each successful build from the branch “production” publish TeamCity artifacts, which is a ready to use JAR-s and scripts that control a set of parameters to run the application. When starting a new instance from the AMI predpochtenija (or restart an existing one) starting script TeamCity uses the latest production build and launch the app using the supplied build script.
Thus, all you need to do for deployment of the new version in production to wait for the end of the tests and click on the “magic” button, restarting the instances. Controlling the set of running instances and sharing the task flow to different RabbitMQ queue, you can conduct A/B testing for user groups.
the
for the record
the
-
the
- Know how your details. Provide random access to any part. [Keywords]: Amazon S3 random access. the
- Use spot requests for savings. [Keywords]: Amazon EC2 spot requests. the
- make Sure to build prototypes based on existing solutions. At least get the experience. As a maximum — will get almost a turnkey solution.
the
And finally I will tell...
In this review article we have described our approach to solve a fairly typical problem. The project continues to evolve, becoming every day more and more functional. We are happy to share their experiences and answer your questions.



Comments
Post a Comment